Considerations¶
As different applications have different requirements, we’ve carefully considered the capabilities that should be included in DistributedLog leaving the rest up to the applications. These considerations are:
Consistency, Durability and Ordering¶
The distributed systems literature commonly refers to two broad paradigms to use a log for building reliable replicated systems (Figure 1). The Pub-Sub paradigm usually refers to an active-active model where we keep a log of the incoming requests and each replica(reader) processes each request. While the Master-Slave paradigm elects one replica as the master to process requests as they arrive and log changes to its state. The other replicas referred to as slaves apply the state changes in the same order as the master, thereby being in sync and ready to take over the mastership if the current master fails. If the current master loses connectivity to the slaves due to a network partition, the slaves may elect a new master to continue forward progress. A fencing mechanism is necessary for the old master to discover that it has lost ownership and prevent it from modifying state after network connectivity is restored.
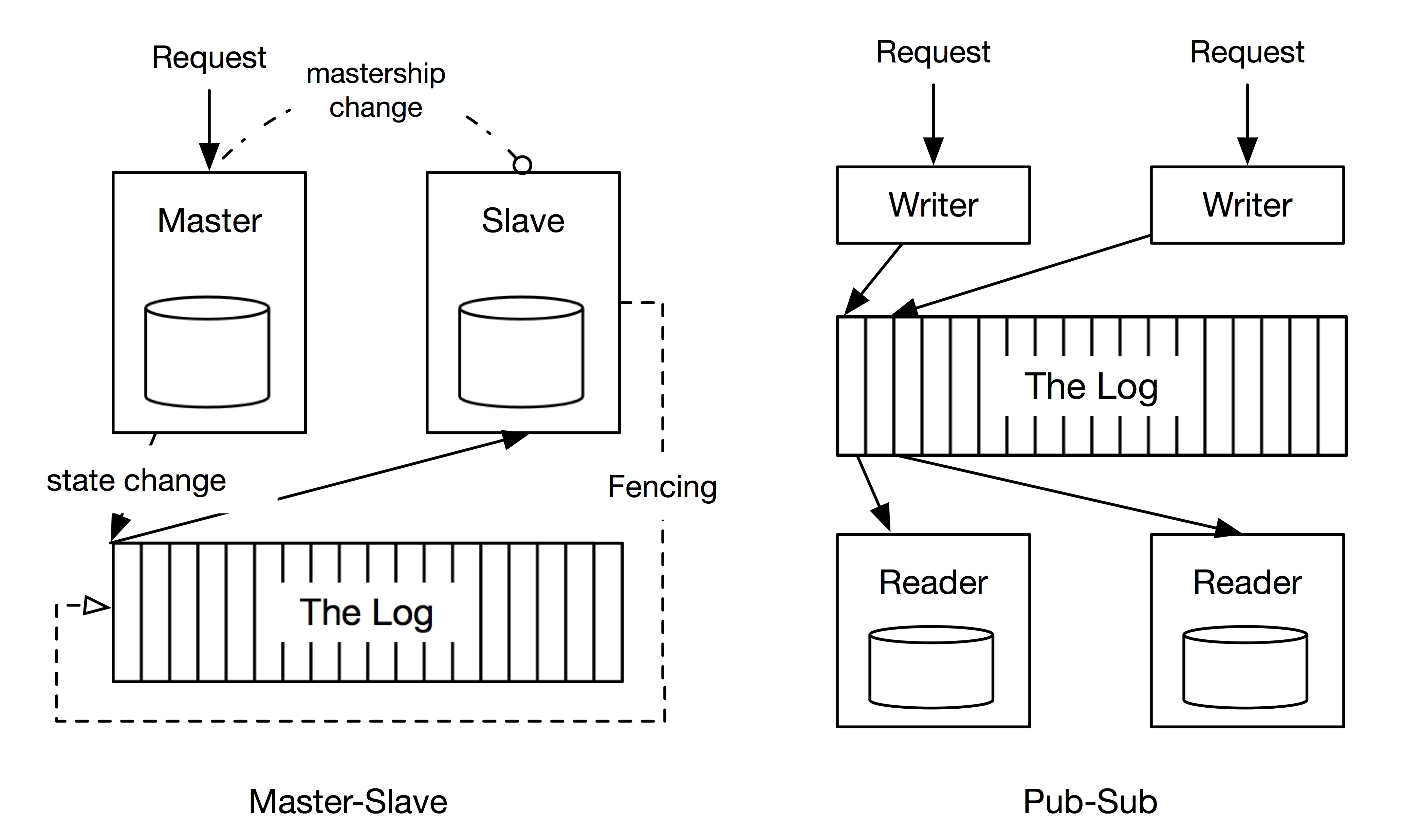
Figure 1. The uses of a log in distributed systems
These two different approaches indicate two different types of ordering requirements - Write Ordering and Read Ordering. Write ordering requires that all writes issued by the log writer be written in a strict order to the log, while read ordering only requires that any reader that reads the log stream should see the same record at any given position, the log records however may not appear in the same order that the writer wrote them. The replicated log service should be able to support both use cases.
Partitioning¶
Partitioning (also known as sharding or bucketing) facilitates horizontal scale. The partitioning scheme depends on the characteristics of the application and is closely related to the ordering guarantees that the application requires. For example, distributed key/value store that uses DistributedLog as its transaction log, distributes the data into partitions each of which is a unit of consistency. Modifications within each partition are required to be strictly ordered. On the other hand, real-time analytics workloads don’t require strict order, can use round-robin partitioning to evenly distribute the reads and writes across all partitions. It is therefore prudent to provide applications the flexibility to choose a suitable partitioning scheme.
Processing Semantics¶
Applications typically choose between at-least-once and exactly-once processing semantics. At-least-once processing guarantees that the application will process all the log records, however when the application resumes after failure, previously processed records may be re-processed if they have not been acknowledged. Exactly once processing is a stricter guarantee where applications must see the effect of processing each record exactly once. Exactly once semantics can be achieved by maintaining reader positions together with the application state and atomically updating both the reader position and the effects of the corresponding log records. For instance, for strongly consistent updates in a distributed key/value store the reader position must be persisted atomically with the changes applied from the corresponding log records. Upon restart from a failure, the reader resumes from the last persisted position thereby guaranteeing that each change is applied only once. With at least once processing guarantees the application can store reader positions in an external store and update it periodically. Upon restart the application will reprocess messages since the last updated reader position.